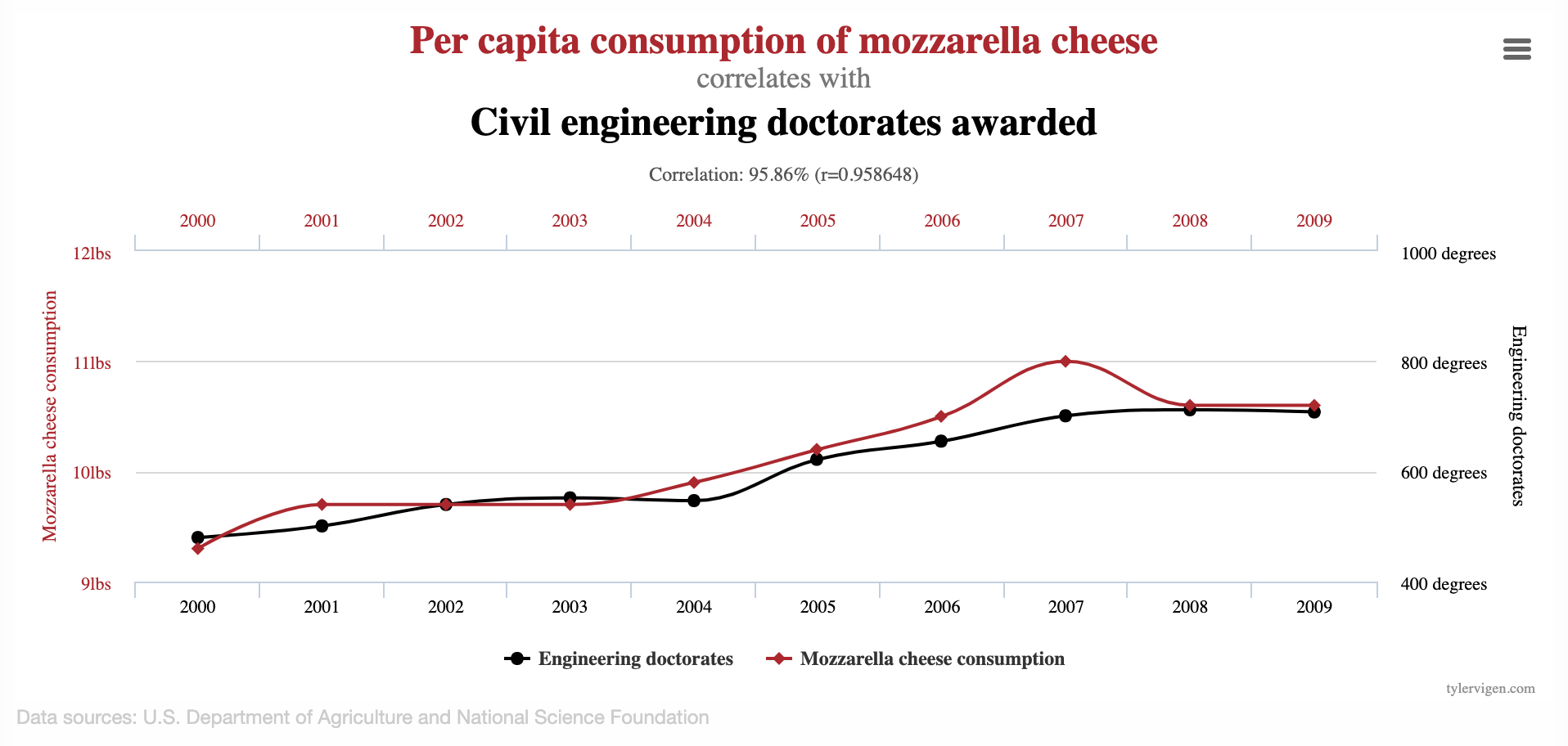
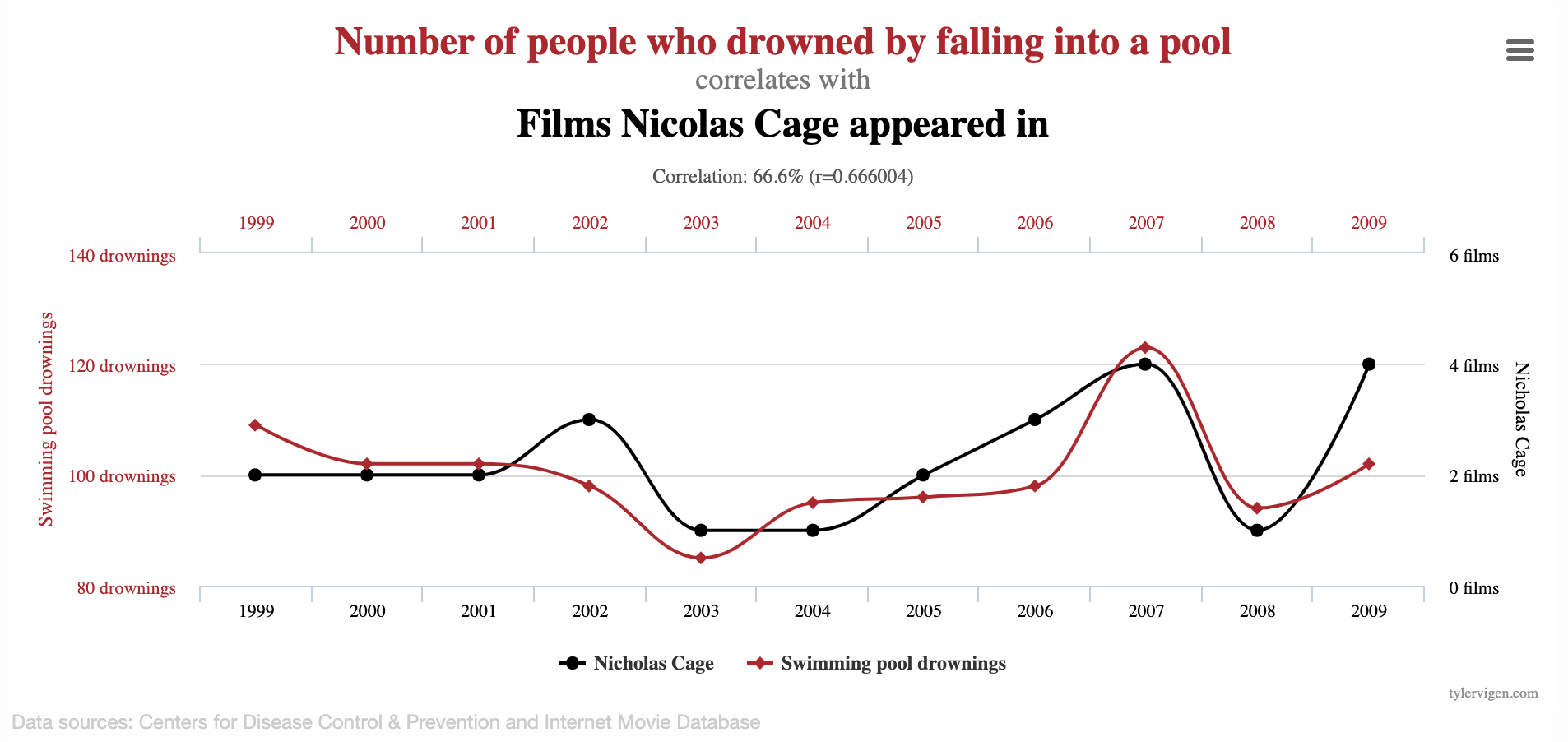
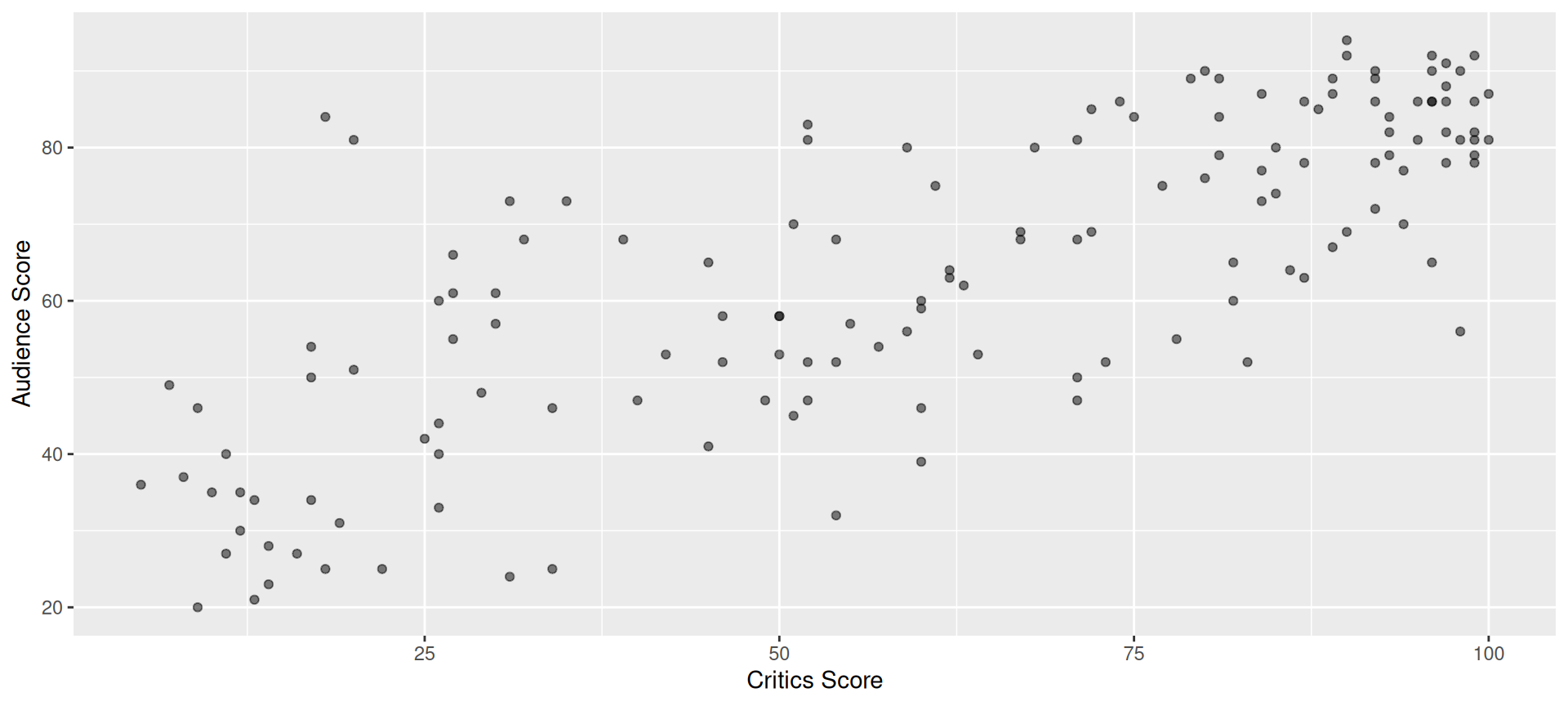
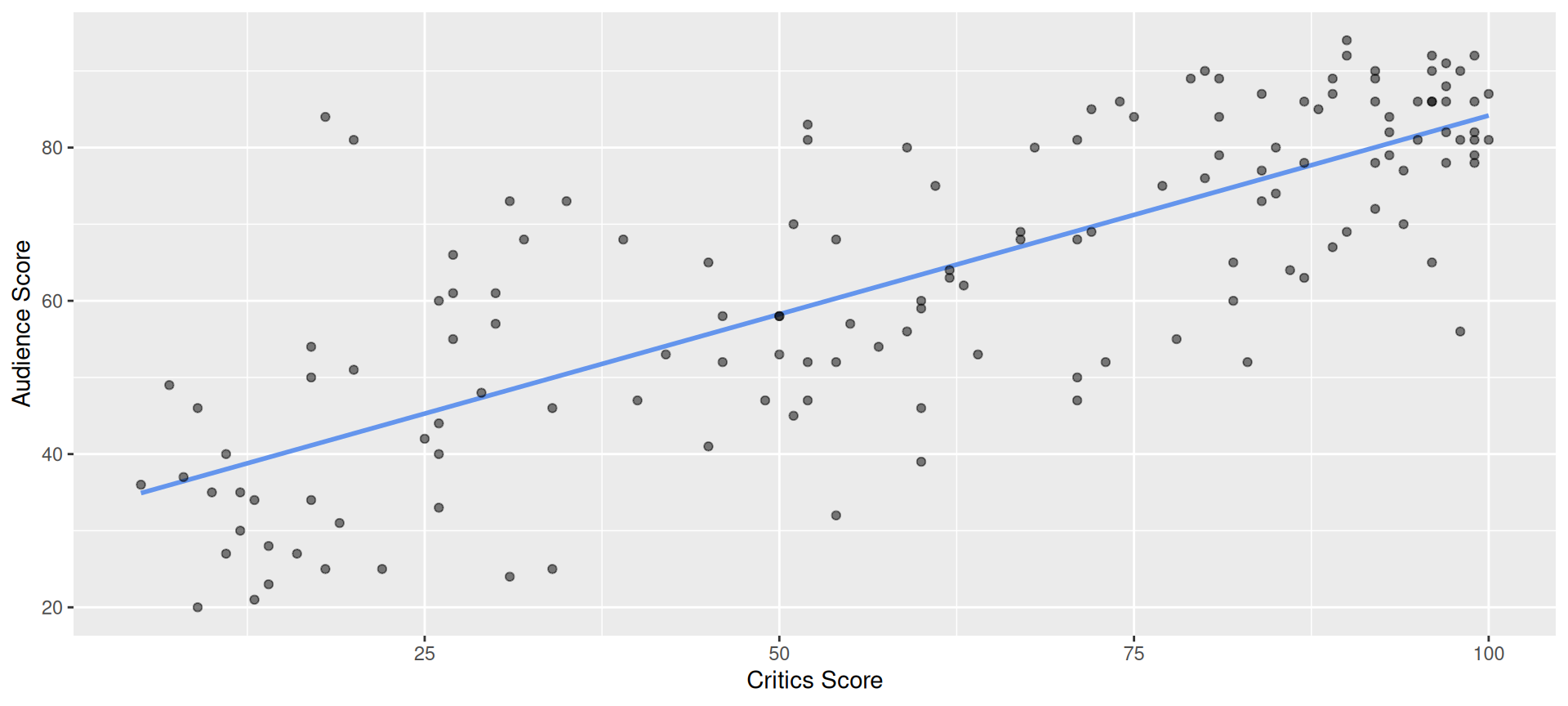
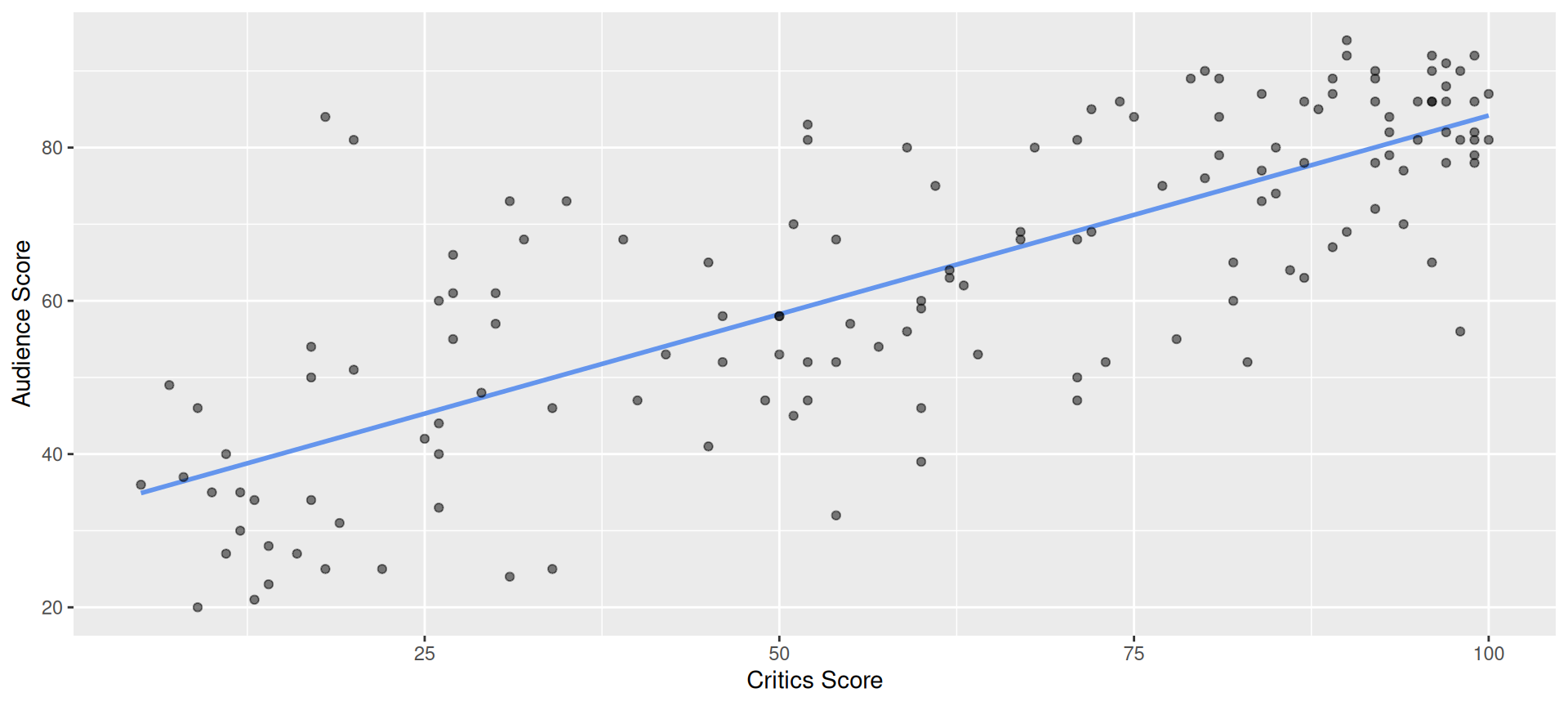
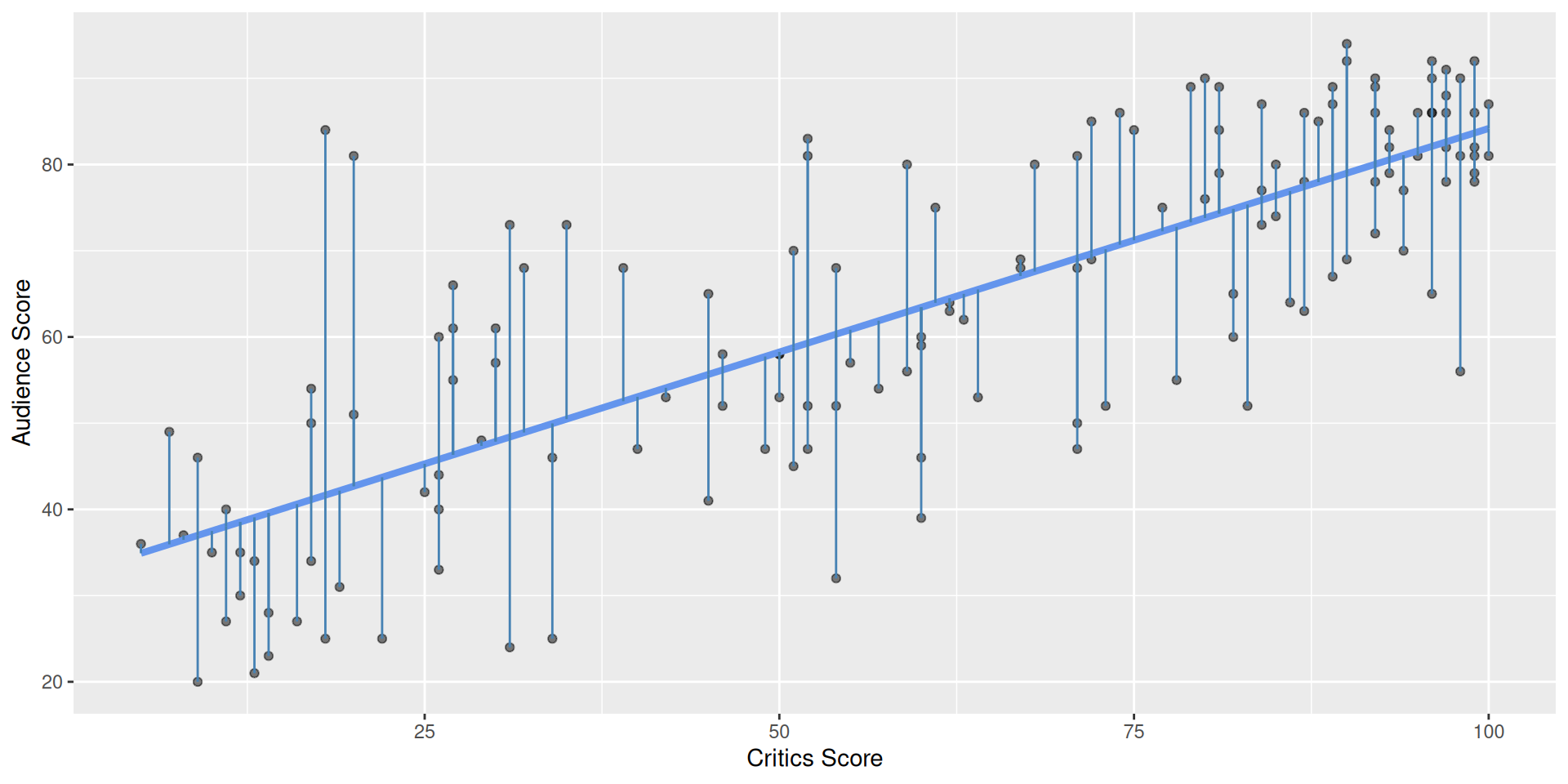
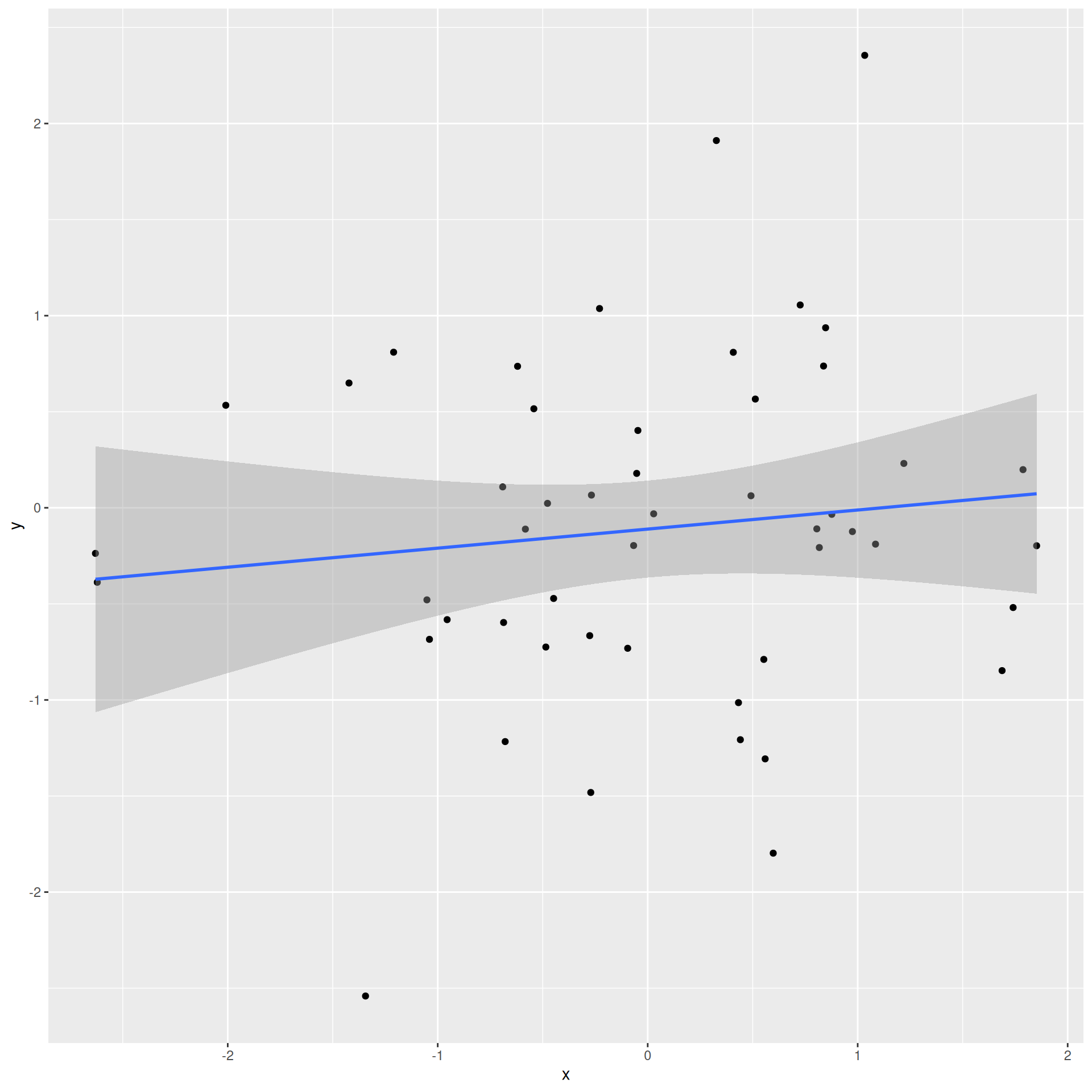
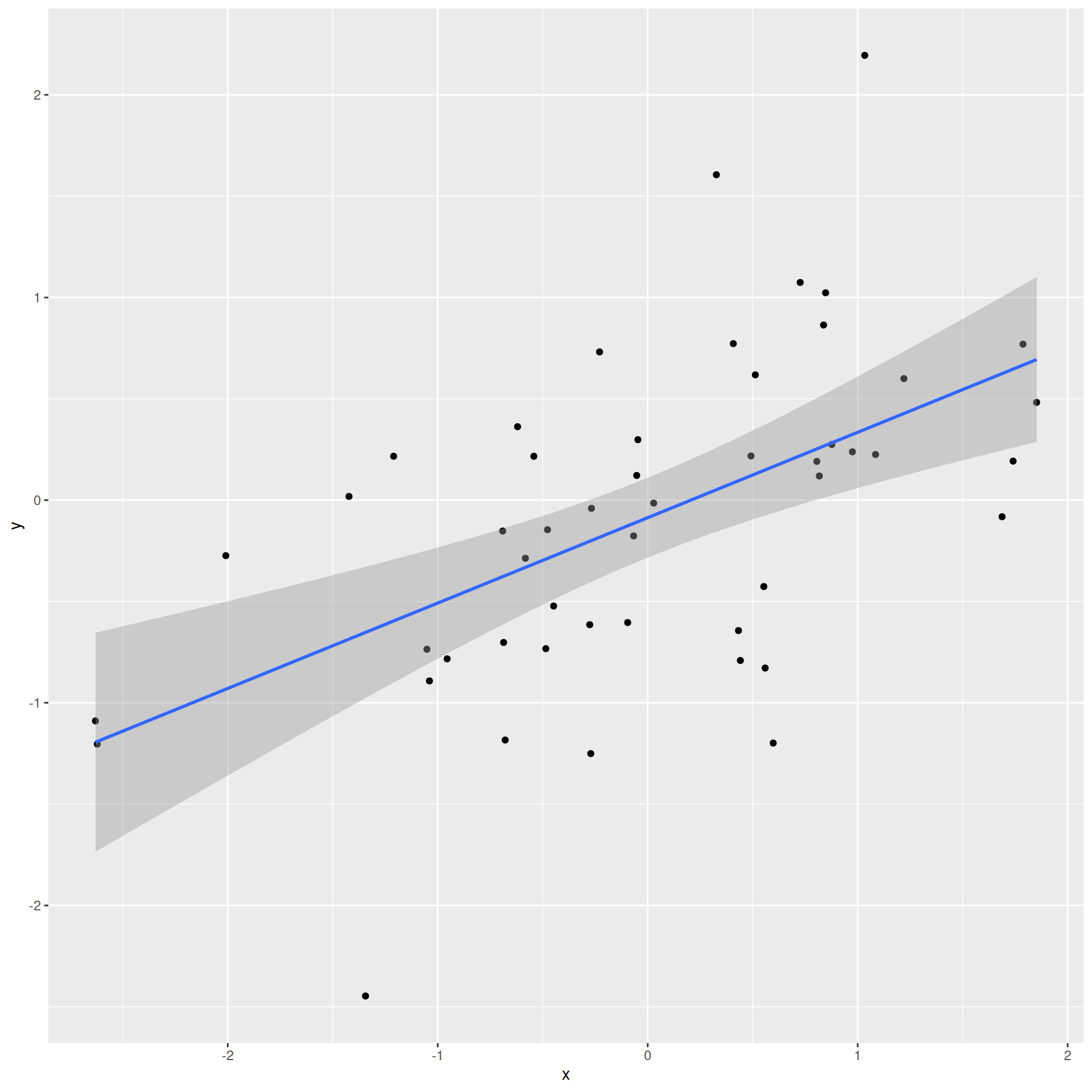
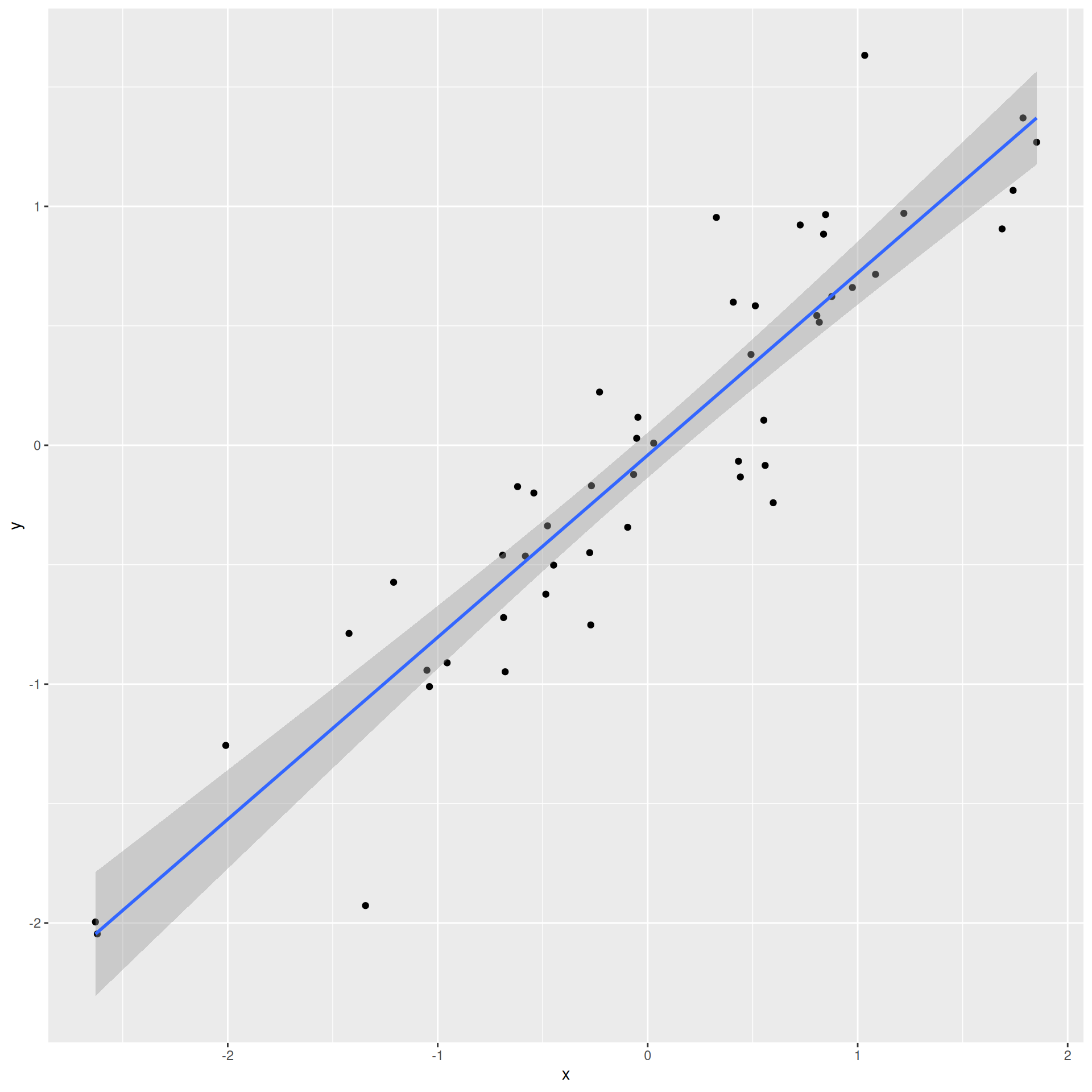
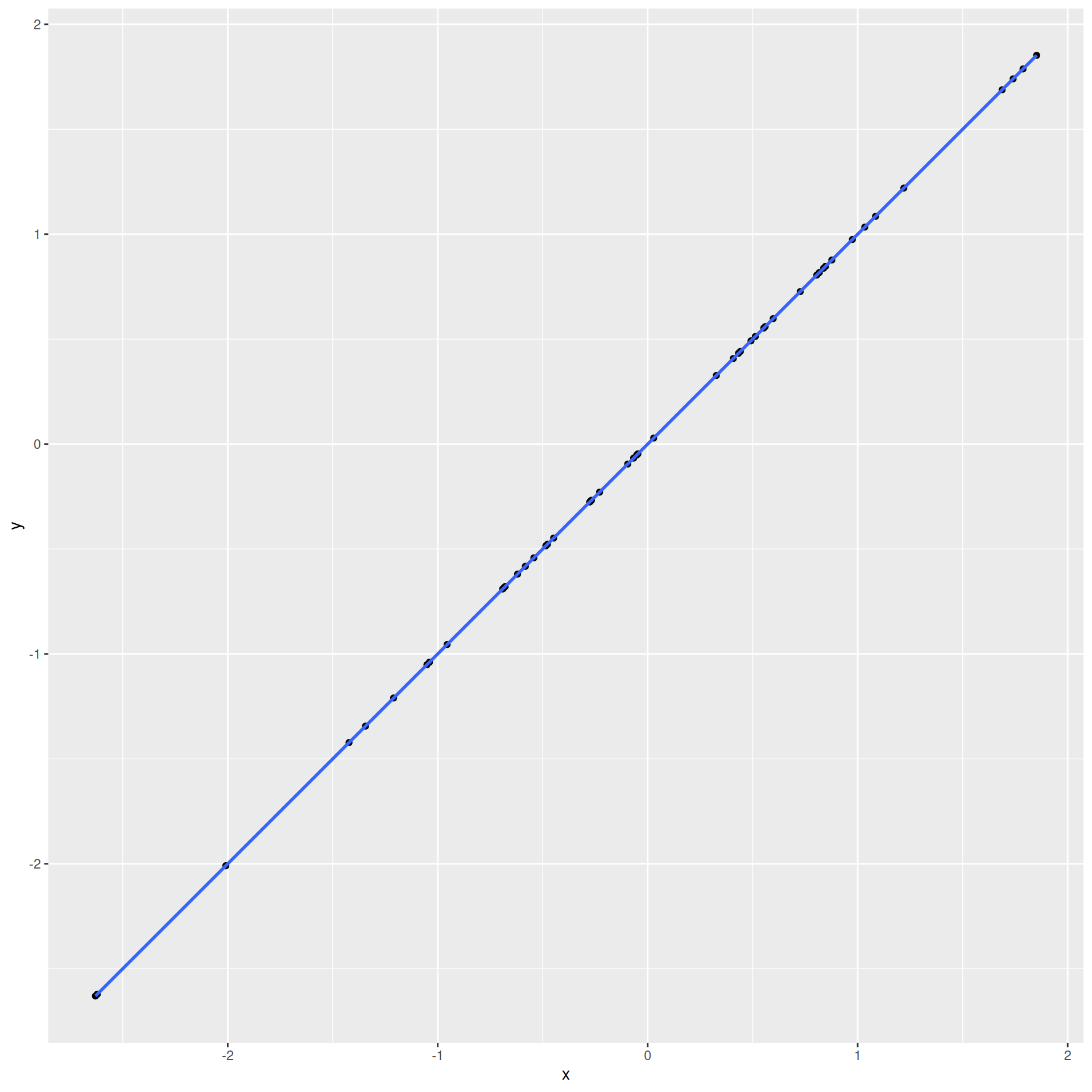
How do we know which variable “should” be the response and which should be the predictor. This will depend on the domain and the research question, but in some cases there is a natural choice. In this example, the critic score for a film is typically available before the audience score. Critics can often screen the film in advance, and their reviews are published on opening day. By contrast, the audience score trickles in over the subsequent weeks. So it’s more likely that we would already have the critics score and use it to anticipate the audience score, instead of the other way around.
Use simple linear regression to model the relationship between a quantitative outcome (\(Y\)) and a single quantitative predictor (\(X\))
The “idealized” linear regression model, revealed only with infinite data:
\[\Large{Y = \beta_0 + \beta_1 X + \epsilon}\]
\(\beta_1\): True slope of the relationship between \(X\) and \(Y\)
\(\beta_0\): True intercept of the relationship between \(X\) and \(Y\)
\(\epsilon\): Error (residual)
Simple linear regression
The “fitted” model, obtained by estimating \(\beta_0\) and \(\beta_1\) using a finite sample (\(x_1, y_1\)), (\(x_2, y_2\)), …, (\(x_n, y_n\))
\[\Large{\widehat{Y} = b_0 + b_1 X}\]
\(b_1\): Estimated slope of the relationship between \(X\) and \(Y\); you may also see \(\widehat{\beta_1}\)
\(b_0\): Estimated intercept of the relationship between \(X\) and \(Y\); you may also see \(\widehat{\beta_0}\)
No error term!
Ideally, as \(n \to \infty\), \(b_0 \to \beta_0\) and \(b_1 \to \beta_1\)
Why did the notation change?
You’re already familiar with \(y=mx+b\), so why did I switch it up on you? Why the subscripts? Why the Greek letters?
Today, we’re studying simple linear regression where there is only one predictor. Tomorrow, we will study multiple linear regression, where there are >1 predictors, and each one gets its own coefficient. When you go from 1 predictor to 5 or 10 or 1,000, you run out of letters. So it’s easier to add subscripts to the same letter, arbitrarily chosen to be \(x\);
The Greek letters denote true, idealized, population values. These are unknown. If we had perfect data, we would know them, but we don’t.
The lowercase roman letters denote estimated values based on a finite, imperfect sample. These are our best guess at the true values based on the data we have.
Choosing values for \(b_1\) and \(b_0\)
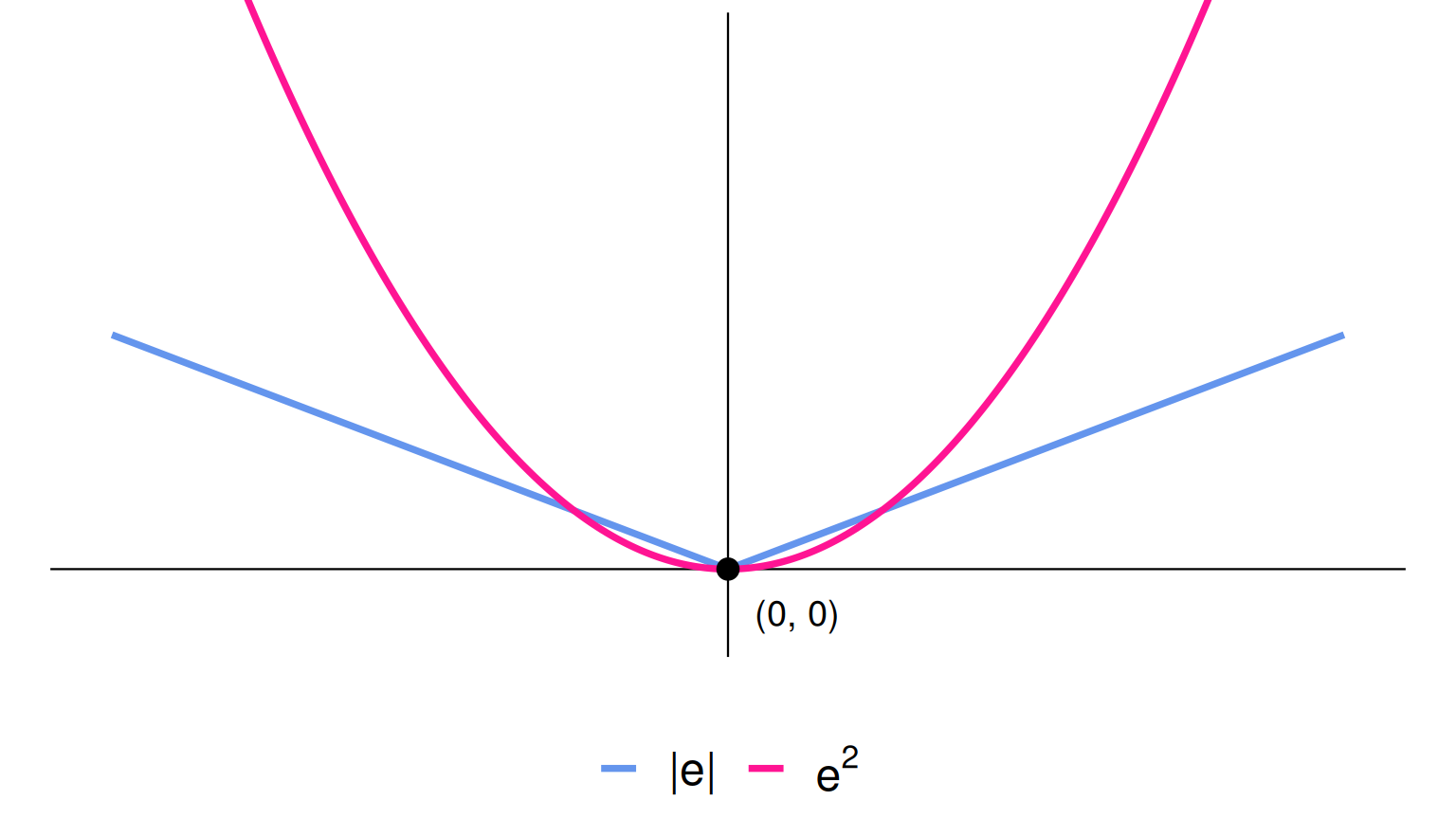
Residuals
\[\text{residual} = \text{observed} - \text{predicted} = y - \widehat{y}\]
Notation
We have \(n\) observations (generally, the number of rows in a df)
\(i^{th}\) observation (\(i\) from \(1\) to \(n\)):
If you recall ggplot, it takes two arguments: a data frame and an aesthetic mapping that specifies what columns to use and how to use them. fit is similar. It takes two arguments: a data frame and a formula that species what variables to include in the model and how.
linear_reg() |>fit(y ~ x, df)
The statement y ~ x is called a formula in R. The variable name that appears to the left of the tilde (~) is treated as the response variable, and the variable(s!) to the right of the tilde are treated as explanatory.
Prediction
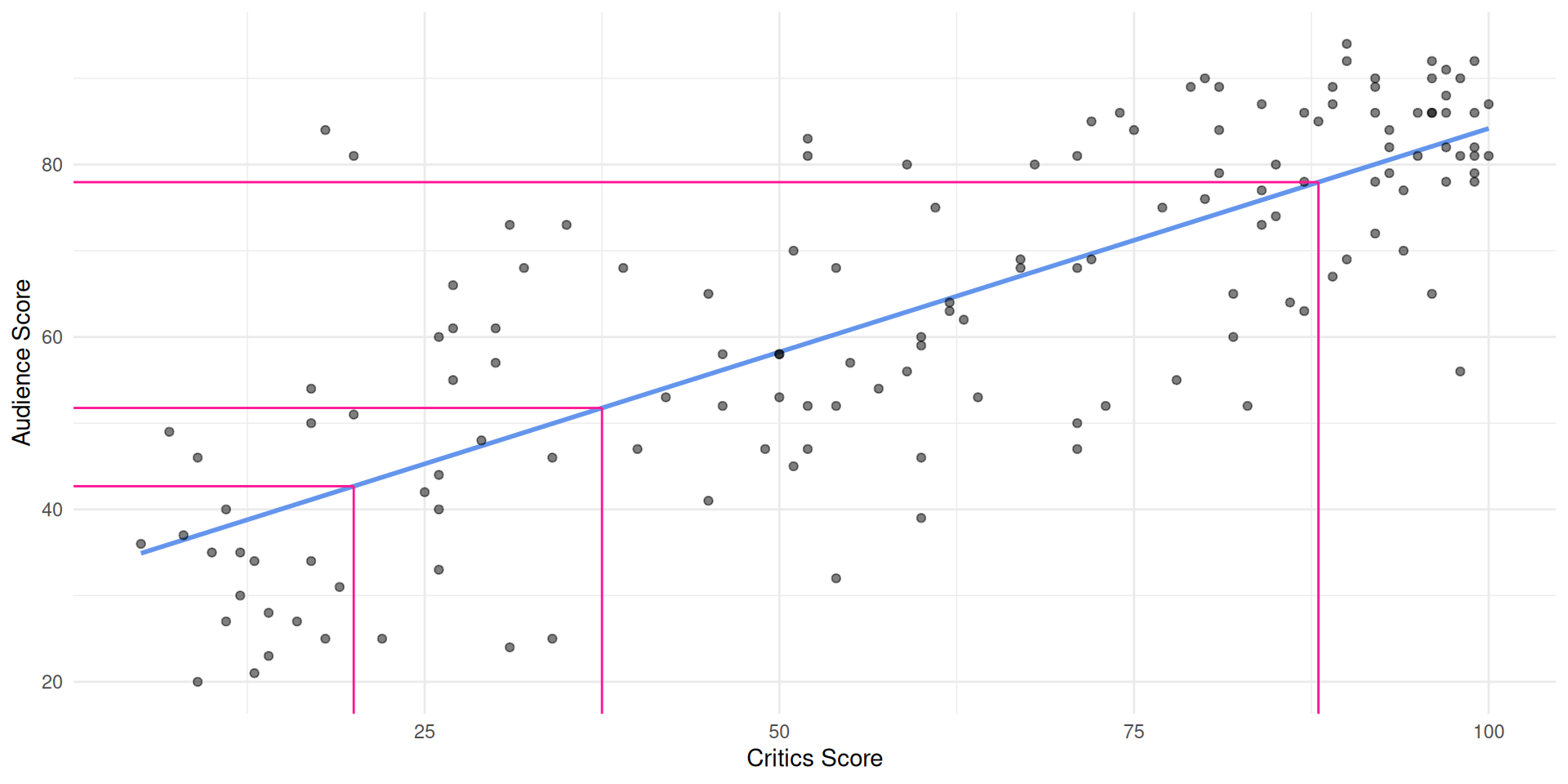
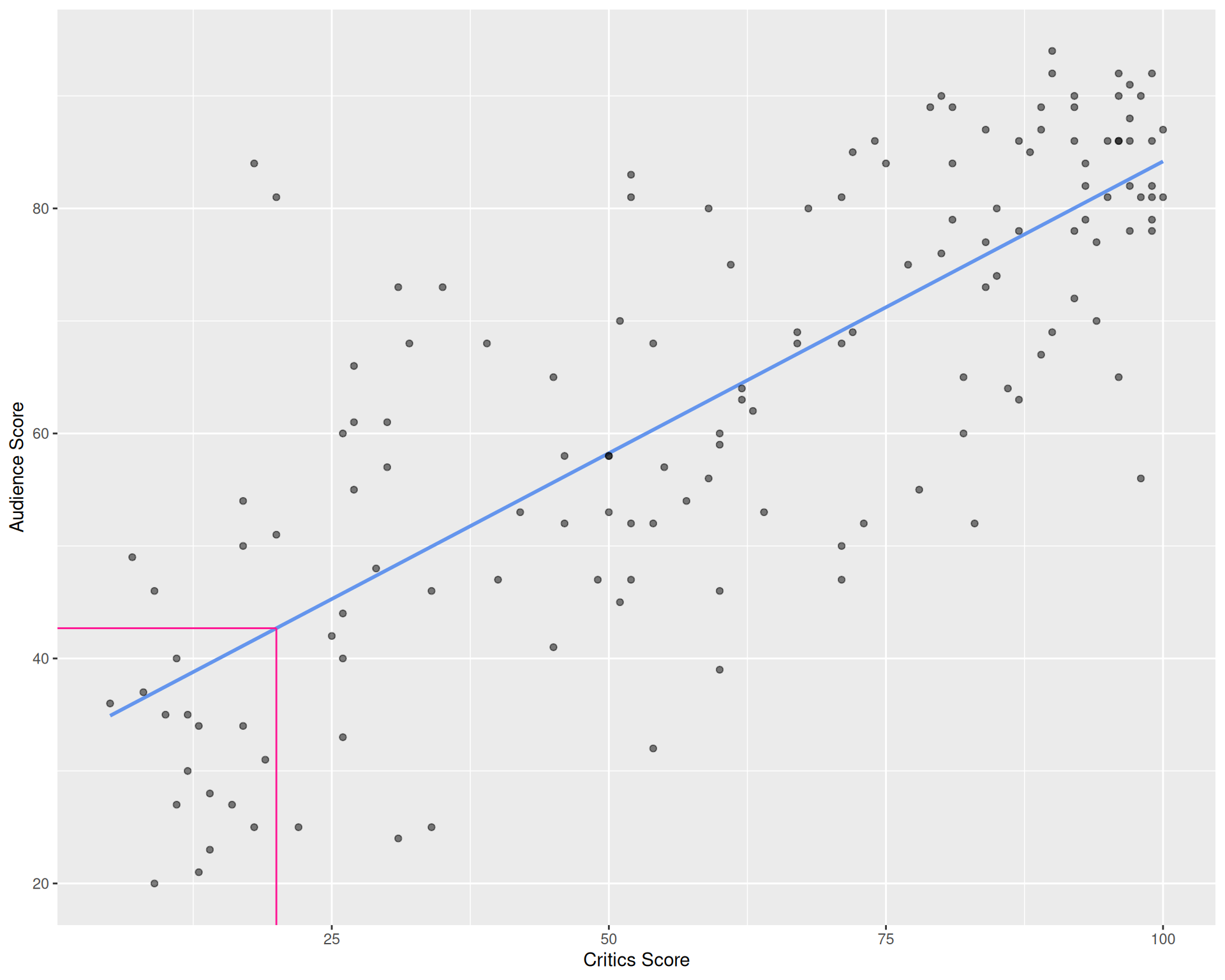
A new movie with a critics’ score of \(x = 20\) is released, and our model predicts that the audience score will be \(\widehat{y}\approx 42.69\), on average:
Slope: for every one point increase in the critics’ score, we expect the audience score to be higher by 0.519 points, on average;
Intercept: for movies with a critics’ score of 0 points, we expect the audience score to be 32.3 points, on average.
The “we expect” and “on average” are a bit redundant, but let’s go belt and suspenders in this class.
Things to watch out for
When interpreting coefficient estimates in a regression:
avoid causal-sounding language;
bad: “a one unit increase in xmakesy go up by 0.519”
don’t make guarantees;
bad: “if x = 0, theny will be 32.3”
do be explicitly predictive;
good: “if x increases by one unit, we expect / predict that y will be higher by 0.519, on average.”
In general, our models give imperfect predictions about average behavior. The predictions are not guarantees, and the relationship may or may not be causal. Establishing that is an entire class in and of itself (causal inference).
Is the intercept meaningful?
✅ The intercept is meaningful in context of the data if
the predictor can feasibly take values equal to / near zero, or
the predictor has values near zero in the observed data
🛑 Otherwise, it might not be meaningful!
For example…
It doesn’t make sense to predict the mpg of a car that weighs 0 pounds;
It does make sense to predict the ice duration of a lake at 0 degree temp;
It does make sense to predict audience score if the critics gave the movie a 0%.
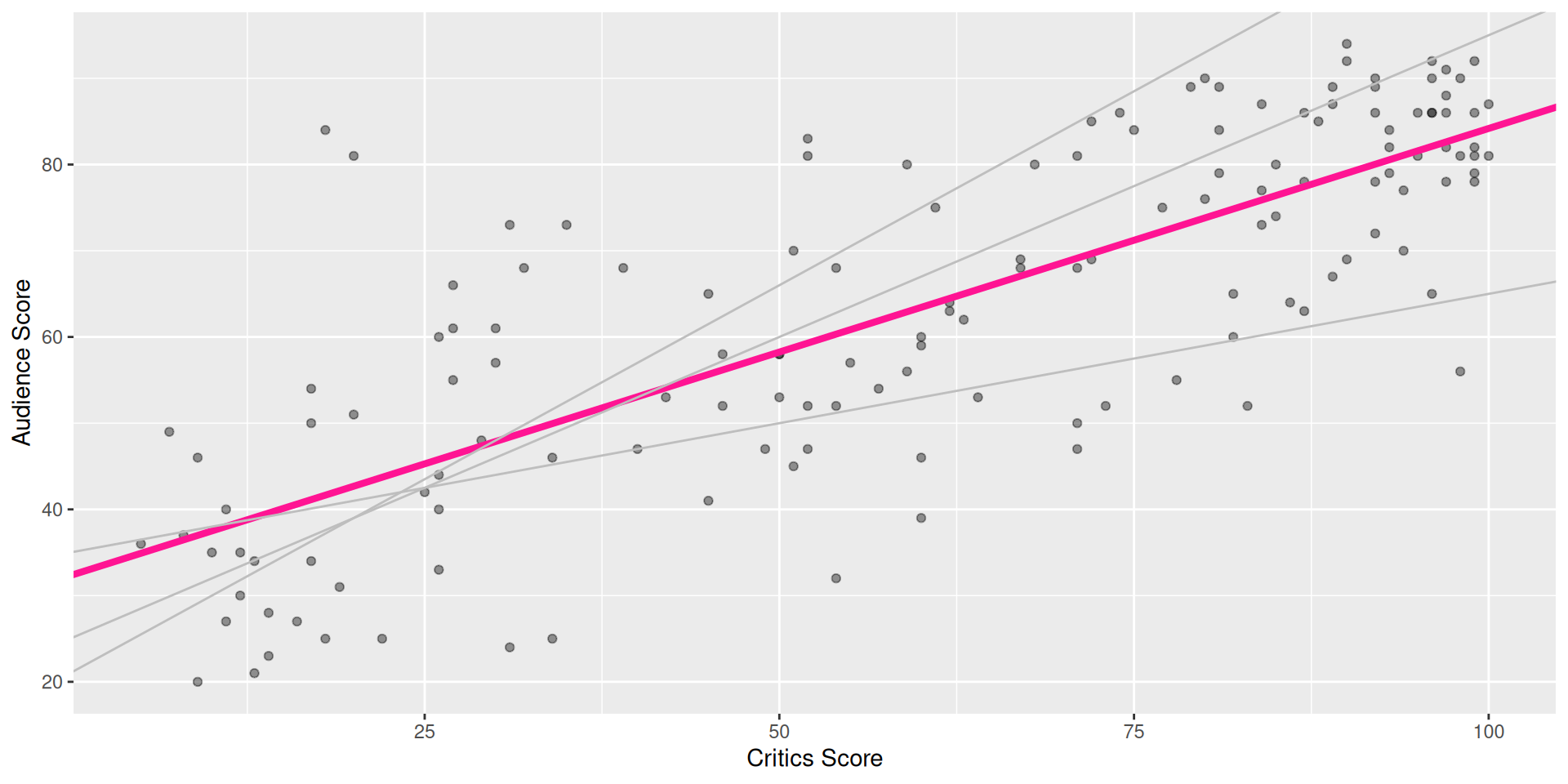
Properties of least squares regression
The regression line goes through the center of mass point (the coordinates corresponding to average \(X\) and average \(Y\) i.e., (\(\bar{x}, \bar{y}\)))
Why? Under LSR (least-squares regression), \(b_0 = \bar{y} - b_1~\bar{x}\); plugging in \(x =\bar{x}\) to the fitted eq., \(\widehat{y} = b_0 + b_1~\bar{x} = (\bar{y} - b_1~\bar{x}) + b_1~\bar{x} = \bar{y}\)
\(\Rightarrow \widehat{y} = \bar{y} \text{ when } x = \bar{x}\)
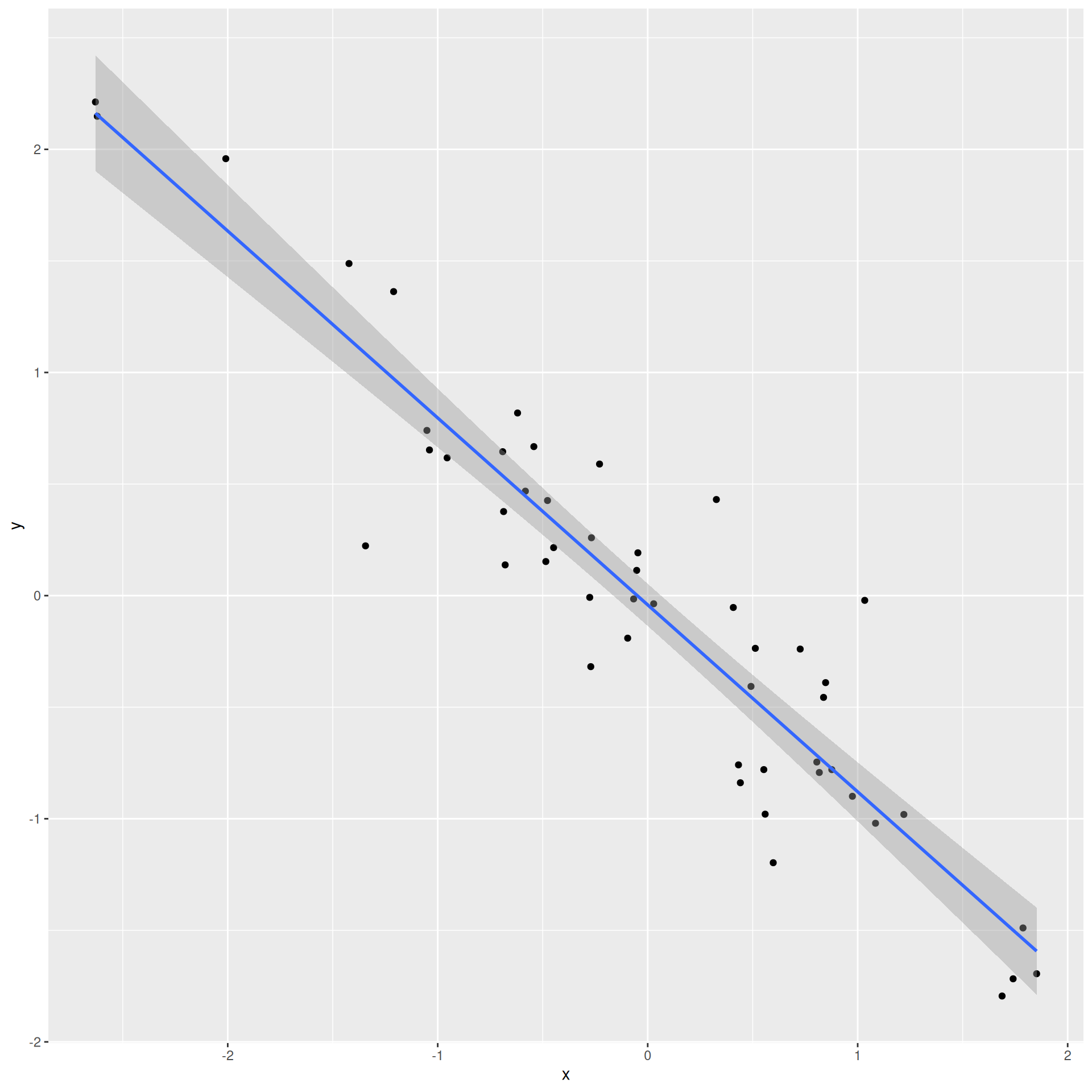
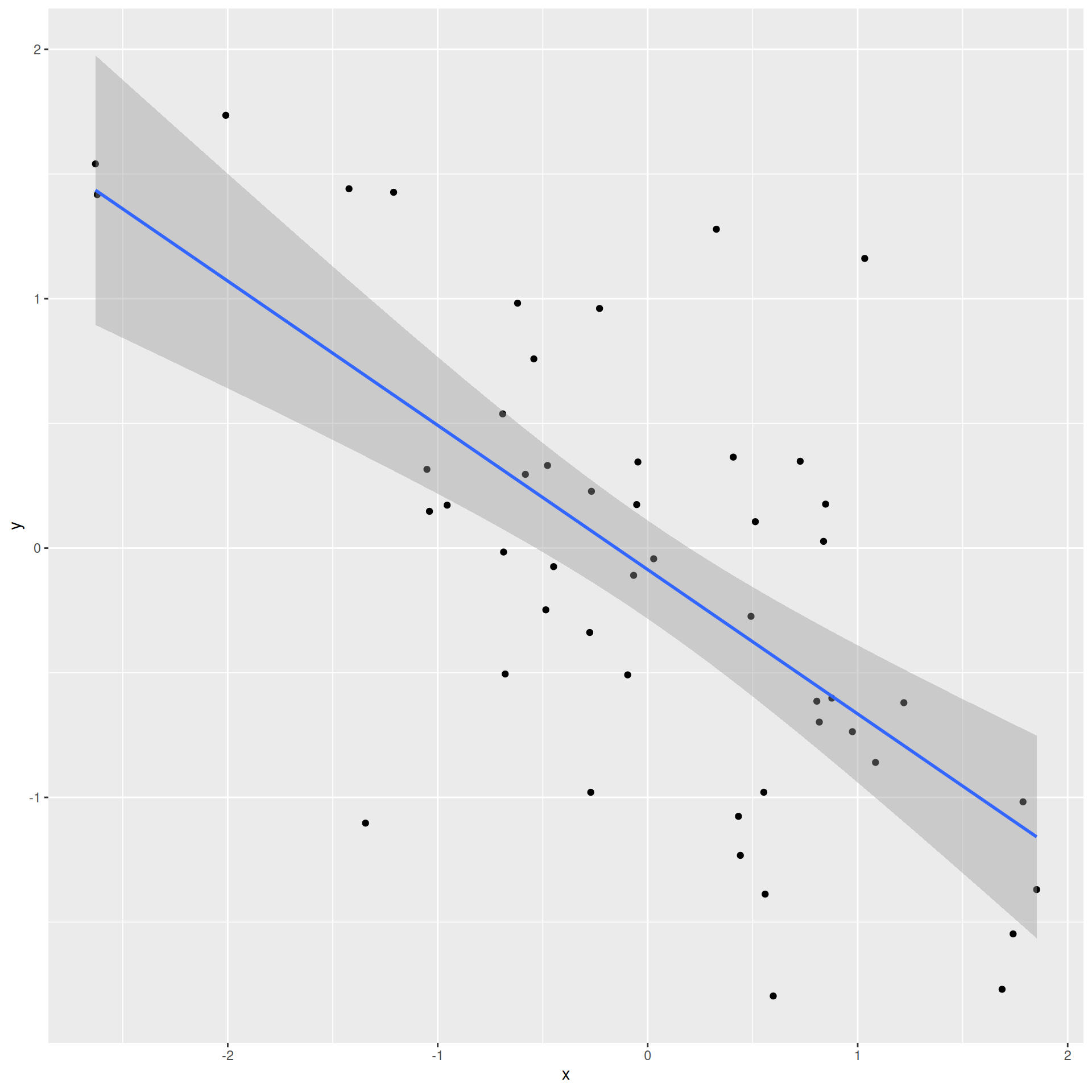
Slope has the same sign as the correlation coefficient: \(b_1 = r \frac{s_Y}{s_X}\)
Sum of the residuals is zero: \(\sum_{i = 1}^n \epsilon_i = 0\)
Residuals and \(X\) values are uncorrelated
Goodness-of-fit
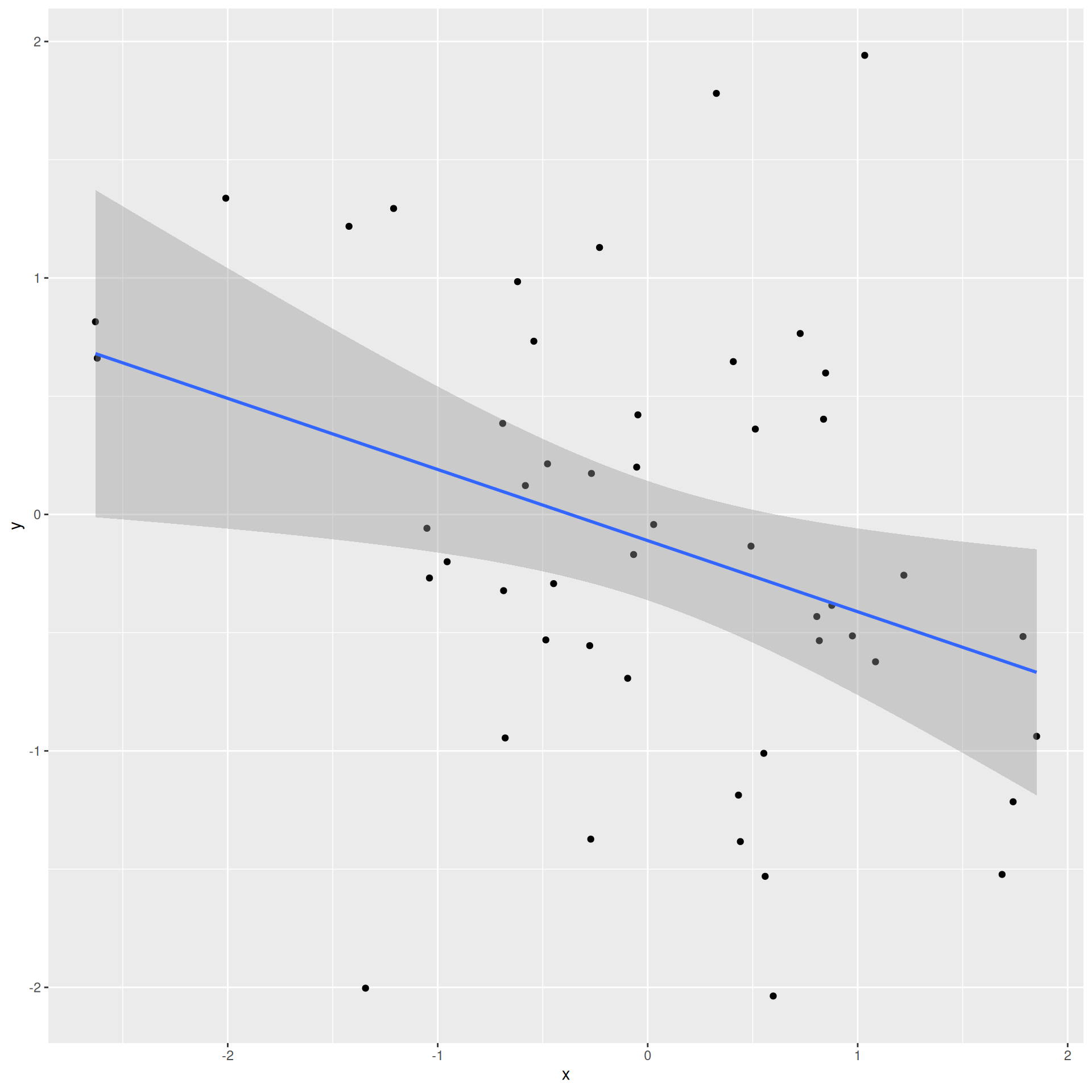
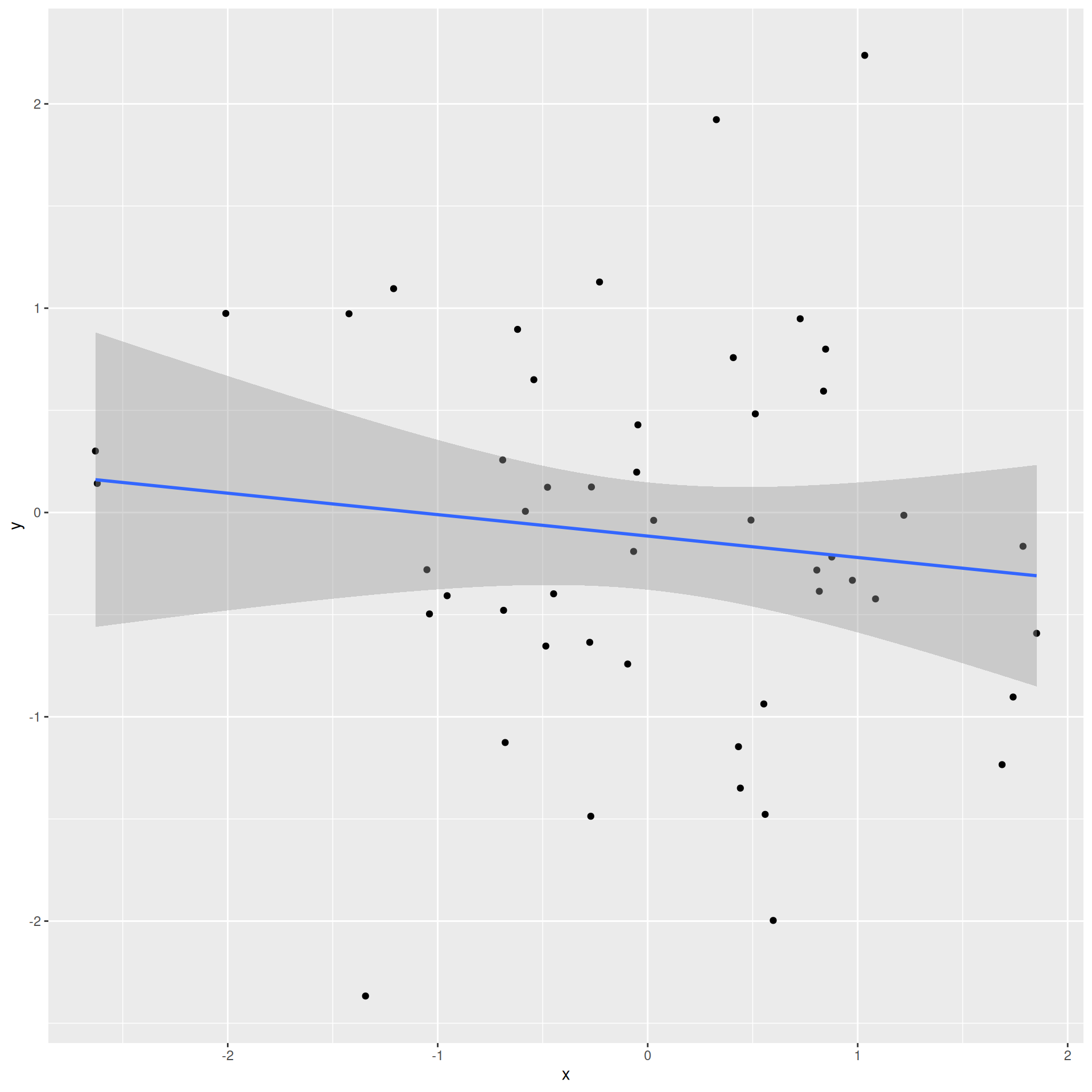
Correlation is a number between -1 and 1 measuring the strength and direction of the linear association between two numerical variables (\(X\) and \(Y\));
If you square it, you get \(R^2\) (“\(R\) squared”) or the coefficient of determination;
This is a number between 0 and 1 measuring how well the linear model fits the data:
\(R^2=1\) means linear fit is perfect;
\(R^2=0\) means linear fit is perfectly wretched;
Technically, \(R^2\) measures the fraction of the variation in the response \(Y\) explained by the model (more on this later).