AE 11: Midterm ‘Live Coding’ Exam Practice 🏀⛹🐧️
Part 1 - NBA Draft Combine
The NBA Draft Combine is a multiple day event that takes place every May before the NBA draft in June. At the combine, college basketball players take medical tests, are interviewed, perform various athletic tests and shooting drills, and play in five-on-five drills for an audience of National Basketball Association (NBA) coaches, general managers, and scouts. How an athlete measures and performs during the combine can affect perception, draft status, salary, and the player’s future career. These stats are posted annually at https://www.nba.com/stats/draft/combine-anthro, which is where the data you’ll be using for this part comes from.
In addition to the tidyverse package, you will also need the readxl and the janitor packages for this part. Your analysis must use these packages.
The data are stored in two sheets of a single Excel file called nba-draft-combine-2425.xlsx, which is in your data folder. The two sheets and their contents are as follows:
- Sheet 1:
"Anthro"- Player names, positions, and anthropometric measurements (i.e., measurements of the body’s dimensions and shape) including:- hand length (in inches)
- hand width (in inches)
- height without shoes (in feet and inches, e.g., 8’ 10.50’’ = 8 feet 10.5 inches)
- standing reach (in feet and inches)
- weight (in pounds)
- wingspan (in feet and inches)
- Sheet 2:
"Strength and Agility"- Player names, positions, and strength & agility measurements including:- lane agility time (in seconds, lower the better)
- shuttle run (in seconds, lower the better)
- three-quarter sprint (in seconds, the lower the better)
- standing vertical leap (in inches, the higher the better)
- max vertical leap (in inches, the higher the better)
In both sheets, positions are given as abbreviations:
- C: Center
- PF: Power Forward
- PG: Point Guard
- SF: Small Forward
- SG: Shooting Guard
If you’re curious, you can read more about basketball positions on Wikipedia.
Question 1 - Import and join
Read each of the sheets in and save them as separate data frames in R, nba_draft_athro and nba_draft_strength_agility. Pay attention to any possible extraneous rows on top of the sheet(s) and handle them as needed. Once the data is in R, convert all variable names to snake_case (lowercase, with underscores instead of spaces). Save the data frames with the cleaned-up variable names with the same names as before, nba_draft_athro and nba_draft_strength_agility.
Note: For full credit on this question, you must use the read_excel() and clean_names() functions. If you’re unable to achieve the goals listed above with just these two functions, you can still get partial credit by using other functions to clean the data after reading it in.
Then, join the two data frames by player name, keeping only the players that are in both data frames. Name the joined data frame nba_draft_raw. Display the data frame and state the numbers of rows and columns in the data frame in a single sentence.
# add code here# add code hereQuestion 2 - Check and clean
Joining the data by player name alone should have resulted in two position variables in nba_draft_raw: position.x and position.y. position.x is the position variable coming from the “left” data frame when you joined. position.y is the position variable coming from the “right” data frame when you joined.
First, check if position.x and position.y are the same for each player. Include a 1-2 sentence description of how you go about checking this – there are multiple ways you can do this.
If yes, remove one of the variables from the data frame, keep the other, and rename it to
position.If no, keep
position.x, removeposition.y, and renameposition.xtoposition.
Either way, save the resulting data frame as nba_draft. Display the data frame and state the numbers of rows and columns in the data frame in a single sentence.
# add code hereQuestion 3 - Help and correct
Suppose you are helping a friend who is working with these data.
- Your friend claims to have created an indicator (binary) variable labeling players who weigh less than 215 pounds (the average weight of an NBA player) as “below mean” and those who weigh 215 pounds or more as “above mean”. They also claim to have added this indicator variable to the data frame
nba_draft.
Here is the code they used:
Upon inspection of this code, you notice several mistakes and areas for improvement. Fix the code to accomplish your friend’s goals, and write a bulleted list describing and justifying each fix or improvement you make (maximum 1 sentence per fix).
# add code here- Your friend has also created a visualization of hand lengths and widths, and they want to color the points blue. But the visualization doesn’t quite come out to be what they want. And they’re also confused about the number of points on the plot; they want to see every player in the dataset represented but there are much fewer points on the plot.
Here is the code they used and the output they got.
ggplot(
nba_draft,
aes(x = hand_length_inches, y = hand_width_inches, color = "blue")
) +
geom_point()
labs(
x = "Hand width (inches)",
y = "Hand length (inches)"
)$x
[1] "Hand width (inches)"
$y
[1] "Hand length (inches)"
attr(,"class")
[1] "labels"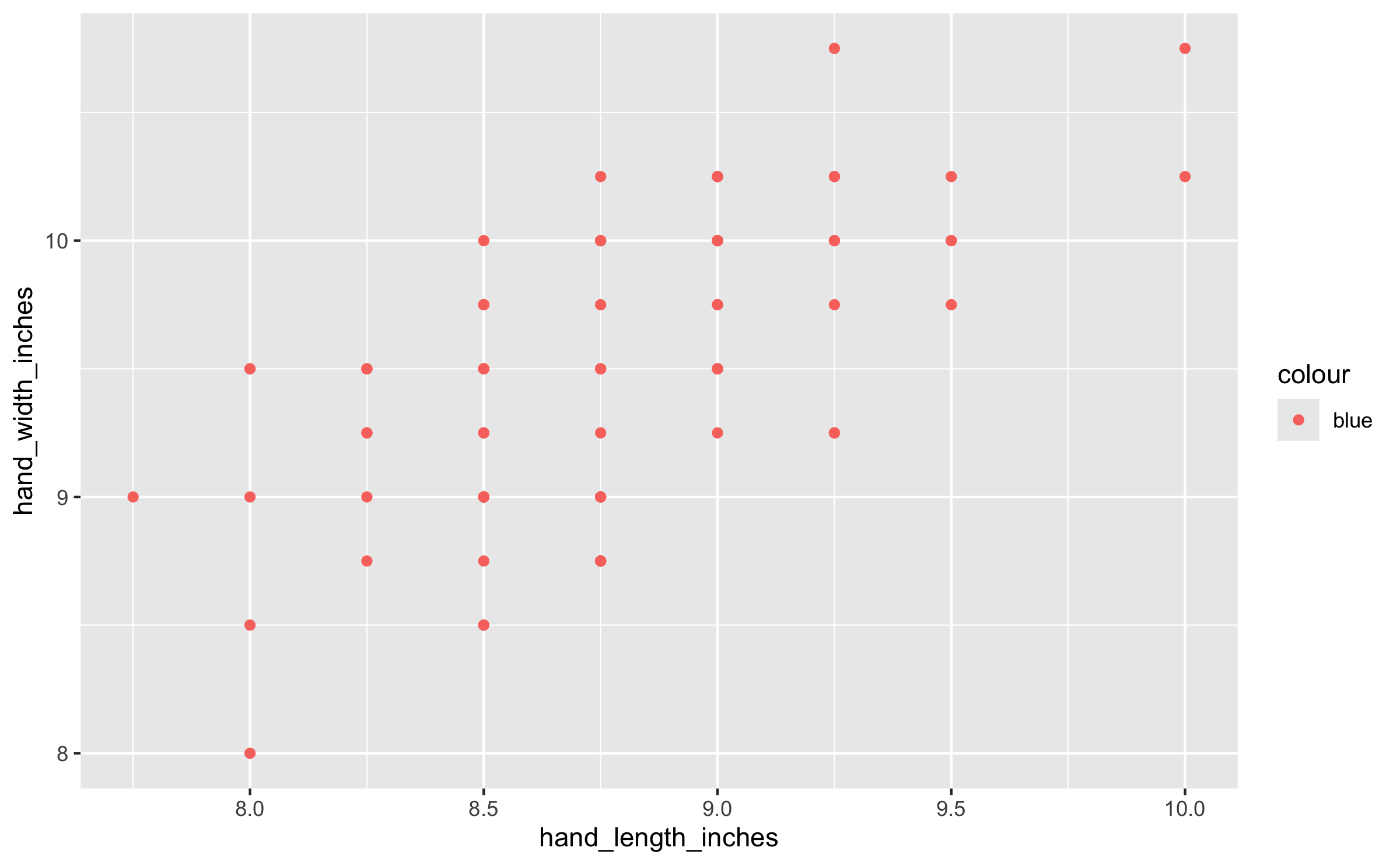
Upon inspection of this code, you notice several mistakes and areas for improvement here as well. Fix the code to accomplish your friend’s goals, and again write a bulleted list describing and justifying each fix or improvement you make (maximum 1 sentence per fix).
# add code herePart 2 - Back to the Penguins
In this part you work with data on the Palmer Penguins.
You will need to load the palmerpenguins package for the data. If at any point you accidentally overwrite the penguins data frame, you can reload the original data frame by typing penguins <- palmerpenguins::penguins into your console.
Question 4 - Tile and scatter
- In a single pipeline, update the
penguinsdata frame to:- remove rows with missing values for
bill_length_mm,flipper_length_mm, orspecies - include a new variable called
bill_length_groupthat dividesbill_length_mminto 4 approximately equal-sized groups usingntile()
- remove rows with missing values for
Then, using the updated penguins data frame as your starting point, create a new data frame called penguin_bill_groups that: - groups by species and bill_length_group - calculates: the number of penguins and the mean flipper length in each group.
The resultant data frame should be ungrouped.
Note You will need to use the function ntile(), which we have not explicitly discussed in class. Use ?ntile to learn what it does.
# add code here-
ntile()attempts to split a vector into equally sized buckets, and in doing so it does not guarantee that tied values will remain in the same bucket. As a result, it is possible that “the same value [within a vector] ends up in different buckets.”
Investigate whether any penguins with the same bill_length_mm were assigned to different bill_length_groups.
If so, identify all bill length values for which this occurred.
Hint: You should use the updated penguins data frame as your starting point, not penguin_bill_groups.
# add code here- Using the
penguin_bill_groupsdata frame you created in part (a), make a plot that shows how mean flipper length varies across bill length groups for each species.
Your plot should:
put bill_length_group on the x-axis,
put mean flipper length on the y-axis,
use color to represent species,
include both points and distinct lines connecting the points for each species,
have an informative title and human-readable axis/legend labels with relevant units.
# add code here